tianle91.github.io
Computations on Distributed Datasets
Overview on the “why’s” and “how’s” of computations on distributed datasets — and what’s this Map-Reduce thing anyway?
Imagine that you need to run some computation on a dataset and if you try to load the dataset, your laptop runs out of memory! What you’d really like is a laptop with more memory, but the best your manager can do is just another identical laptop. Now, theoretically you have double the total memory and computational power. But how do you actually use both machines? Your manager assures you that it’s possible, but before he can say more, he rushes off for his next meeting.

Partitioning
Before we run any computation, let’s figure out how to split the dataset up and load the pieces into each laptop. That’s not too hard — all we need to do is write the first half of the dataset into the first piece and the second half into the second piece.
dataset_1 = ...
dataset_2 = ...
for row_number, row in dataset:
if row_number < total_rows / 2:
dataset_1.append(row_i)
else:
dataset_2.append(row_i)
Voila! We find that splitting the dataset into two allows each piece to be loaded into their respective laptops without running out of memory. We can now think about how to perform computation on these dataset pieces.

In general, splitting up a large dataset into smaller ones is known as “partitioning”. Partitions should be small enough to be loaded into each worker (that’s a laptop in this example).
A simple computation
Now that we have a dataset split into two separate machines, we can start to think about how to perform computation!
Problem: What is the number of rows in the dataset for which column A has value X?
If we could load the dataset on a single device, we may implement a function as follows to obtain the result:
def count_values(dataset):
n = 0
for row in dataset:
if column X in row has value Y:
n = n + 1
return n
But we couldn’t (because the full dataset couldn’t fit into a single laptop) ! Fortunately, the problem we’re exploring has a useful structure. The count over the entire dataset is simply the sum of the counts over the partitions!
count_1 = count_values(dataset_1)
count_2 = count_values(dataset_2)
# since dataset = dataset_1 + dataset_2
count_values(dataset) = count_1 + count_2
This means that to obtain the counts over the entire dataset, we do not need to load the entire dataset. Instead, we can load up partitions of the dataset and run the computation on each partition. Then we can simply add the counts to obtain the result.
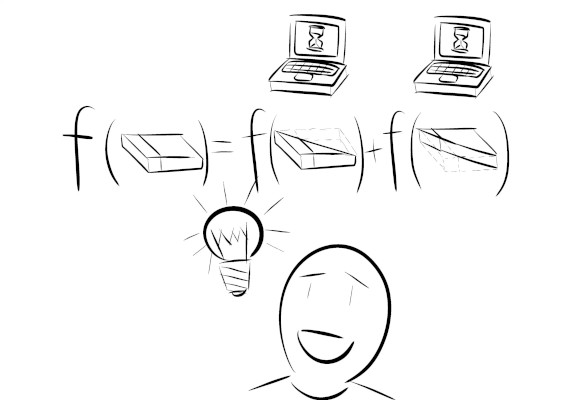
Map and Reduce
Some problems like the one we looked at earlier can be broken up into smaller and independent sub-problems. This class of problems can be solved by a map and reduce operation.
- A map operation distributes a single computation to a set of inputs.
- A reduce operation takes a set of inputs and returns a single value. Let’s revisit the problem we looked at earlier and identify these operations.
Problem: What is the number of rows in the dataset for which column A has value X?
- Split up the dataset into partitions.
- What is the number of rows in each partition of the dataset for which column A has value X? (map operation)
- Add up the counts (reduce operation).
Turns out, the set of operations which can be broken down into map and reduce components is massive! Examples include sums, products, mean, standard deviation, etc. For more examples, see Spark SQL functions.
However, some operations require modifications. For example, finding quantiles on a distributed dataset is often an inexact operation (see Spark SQL ApproxQuantile).
Map-reduce operations also tend to be faster, since the independent tasks in the map operation can be worked on in parallel, so long as the number of workers available is at least the number of partitions.
Check out this notebook: Introduction to Map Reduce operations in Spark. There’s a couple of simple examples using data-frame operations and a simple exercise to get you comfortable with the concept.